A Deep Dive into Low-Level Hardware Access with C: Examples for RISC-V
The C programming language provides a thin hardware abstraction that allows us to create low-level systems programs. However, there are still many hardware features that aren’t exposed by the programming language. How do we access hardware while programming in C?
This article captures experience with low-level programming in C gained by bringing up early firmware on custom SoCs. The examples are for RISC-V machines, but the techniques apply to any architecture. It covers various topics, including interrupt handling, memory-mapped IO, and system calls, while building a simple bare-metal runtime environment.
The target hardware is a RISC-V RV32I in machine mode. The RISC-V is a simple architecture well suited to understanding low-level programming, and a small 32-bit core is ideal for applications that benefit from bare-metal programming.
Finally, there is a PlatformIO project that allows you to run and step through the code examples in the article, and a GitHub CI workflow.

Overview
This article is will walk through an example of using vectored interrupts on RISC-V, covering this set of topics.
- Calling Convention at Reset / Using a C Function as the Reset Vector
- Calling Convention at Reset / Initializing the ABI before calling C Code
- Working with the Linker / Locating the Reset Vector
- Working with the Linker / Accessing Initialization Data
- Handling Interrupts / Using a C Function as an Interrupt Handler
- Handling Interrupts / Using a C Function as an Interrupt Vector Table
- Handling Interrupts / Accessing the Interrupted Stack Frame From C
- Handling Interrupts / Aligning C Functions using a Pragma
- Handling Interrupts / Weak Function Linking to Allow Optional ISR Implementation
- Accessing the Machine / Using System Registers to Control Interrupts
- Accessing the Machine / Accessing Memory Mapped Registers to Manage the Timer
- Accessing the Machine / Using Compiler Macros to Customize for the Architecture
- Accessing the Machine / Built-in functions
- Bringing it All Together / Implementing Interrupt Handlers
- Bringing it All Together / Implementing Exception Handlers
- Bringing it All Together / Implementing a System Call
- Bringing it All Together / Handling a System Call
- Bringing it All Together / The Main Function
- Building and Running / PlatformIO IDE
- Building and Running / Command Line/CI
The Toolchain
It’s essential to understand the toolchain when doing low-level programming. This article will look at these toolchain features:
- Inline Assembler that gives direct access to the target CPU instructions and registers.
- Function Attributes and Variable Attributes change the way code is generated for functions and variables. This includes many that are machine specific, such as RISC-V function attributes.
- Built-in Functions that provide a C function call-like interface to hardware features.
- Pragmas to enable and disable compiler features and modes.
- The Linker, in particular, becoming familiar with the linker script.
This article won’t go into the details of these features, but will instead give examples of how to use them. Often they must be combined to achieve the desired result. An understating of the machine model is also needed, In particular, the ISA and ABI.
A Warning
This article is not about modern best-practice programming. This article is about peeking and poking into hardware to wiggle logic values in wires and make things happen.
Calling Convention at Reset
Using a C Function as the Reset Vector
At reset, how does the processor start executing our C code?
For a RISC-V processor, the reset process involves setting the PC to the _enter function address and executing code at that address. The actual address of _enter is implementation defined. Also note; a C function at this address can't be "called" as calling a C function requires the stack to be initialized.
To define a reset handler in C that can be executed without a stack, the naked function attribute can be applied to the function prototype. This attribute disables stack access in the prologue/epilogue code generated by the compiler.
void _enter(void) __attribute__ ((naked));Initializing the ABI before calling C Code
After reset, when can we start to execute normal C code?
The ABI requires a set of registers to be initialized before C code can be executed:
- The
spstack pointer must be initialized to point to an area of memory reserved for the stack in the linker script. (Our linker script has defined this address as_sp.) - The
gpglobal pointer must be set to the base address for offset addressing. (The linker script has defined this address as__global_pointer$.) - Once the stack is defined perform it’s possible to jump to a C routine,
_start, without pushing the state to the stack.
Our _enter function uses inline assembler to directly initialize these processor registers before calling _start:
void _enter(void) {
// Setup SP and GP
// The locations are defined in the linker script
__asm__ volatile (
".option push;"
".option norelax;"
"la gp, __global_pointer$;"
".option pop;"
"la sp, _sp;"
"jal zero, _start;");
// This point will not be executed, _start() will be called with no return.
}As it is a naked function it uses basic asm.
A GP register is an architectural choice made by many RISC architectures, including RISC-V, but not universal. For example, ARM Cortex-M does not use one.
Working with the Linker
The linker script integrates our C program into the target memory layout. These examples are based on metal.default.lds provided by SiFive.
Locating the Reset Vector
How does the processor know to call _enter at reset?
The _enter function needs to be located at a pre-determined address called the reset vector. To locate a function at the reset vector address in C the section function attribute can be used in conjunction with the linker script.
In this example, the .enter section is used to place the _enter function at the start of ROM memory. On our target this is 0x20010000. This address then executed at reset. For RISC-V the exact address is implementation defined, and may even depend on some boot-rom embedded within an SoC.
MEMORY {
rom (irx!wa) : ORIGIN = 0x20010000, LENGTH = 0x6a120
}
SECTIONS {
.init : {
KEEP (*(.enter))
...
} >rom :rom
}The previous C function declaration for _enter needs to be updated to locate it in this .enter section.
extern void _enter(void) __attribute__ ((naked, section(".enter")));Accessing Initialization Data
If we have global variables, how are they initialized in RAM before our program is run?
As RAM is in an unknown state at boot, all globals are undefined by default.
The linker and compiler define sections in the application image and program memory to hold and receive default values.
- The
bsssection contains global variables with no initial value. The SRAM allocated to these variables is cleared to 0. - The
datasection contains global variables with initial values. These values are copied from read-only memory (FLASH/ROM) to SRAM.
Other sections relate to code regions to be initialized, or used in initialization.
- The
itimsection is a code section that is to be copied to and executed from SRAM to improve performance. - The
initandfiniarrays are tables of constructor and destructor function pointers for global variables.
As we are creating our own run-time environment we need to initialize RAM ourselves. The start-up routine uses the above sections located in (FLASH/ROM) to perform initialization of the corresponding sections in RAM. An important section is the data segment. This holds the initial values for all global variables.
A simplified sample of the linker script is here:
MEMORY
{
ram (arw!xi) : ORIGIN = 0x80000000, LENGTH = 0x4000
rom (irx!wa) : ORIGIN = 0x20010000, LENGTH = 0x6a120
}
SECTIONS
{
...
.data : ALIGN(8) {
*(.data .data.*)
.....
} >ram AT>rom
....
PROVIDE( data_source_start = LOADADDR(.data) );
PROVIDE( data_target_start = ADDR(.data) );
PROVIDE( data_target_end = ADDR(.data) + SIZEOF(.data) );
...
}The symbols defined with PROVIDE are accessible from the C program. The start-up code below copies from one linker defined .data section at data_source_start in ROM to the .data section at data_target_start in RAM.
The linker symbols represent objects at the address of the linker segment start or end, so we take the address of these symbols, e.g. (void*)&data_target_start, or use the delta of the addresses to get the length, e.g.(&data_target_end - &data_target_start).
extern const uint8_t data_source_start;
extern uint8_t data_target_start;
extern uint8_t data_target_end;
...
void _start(void) {
...
// Initialize the .data section (global variables with initial values)
__builtin_memcpy((void*)&data_target_start,
(const void*)&data_source_start,
(&data_target_end - &data_target_start));
...
int rc = main();
...
}The use of memcpy() at this point is possibly problematic as it introduces a standard library dependency, so a GCC built-in __builtin_memcpy() is used
instead, as it should be the most efficient copy the compiler can
implement.
Handling Interrupts
Interrupts are signals from the hardware indicating that it needs attention. They can be called at any time during our C program’s execution (asynchronously), and a critical requirement is that the program can resume when they are finished.
Using a C Function as an Interrupt Handler
When an interrupt occurs, can it be serviced by a C function?
An Interrupt Service Routine(ISR) is a function called when a processor services an exception or an interrupt. Unlike a normal function, it must save all registers to the stack, and use a special return instruction. The interrupt function attribute can turn a C function into an ISR. In general, it will:
- customize the prologue/epilogue code generated by the compiler so all registers are saved; and
- use an interrupt return instruction, such as mret, to return from the function.
RISC-V defines CPU Modes such as machine and supervisor, and this mode is passed as an argument to the attribute.
/** Machine mode exception handler */
void riscv_mtvec_exception(void) __attribute__ ((interrupt ("machine")) );
/** Supervisor mode exception handler */
void riscv_stvec_exception(void) __attribute__ ((interrupt ("supervisor")) );
/** Machine mode timer interrupt */
void riscv_mtvec_mti(void) __attribute__ ((interrupt ("machine") ));
/** Supervisor mode timer interrupt */
void riscv_stvec_sti(void) __attribute__ ((interrupt ("supervisor")) );(An exception to this is the ARM Cortex-M, that processor is designed to enter interrupt handlers in a way consistent with it’s ABI.)
Using a C Function as an Interrupt Vector Table
What about vectored interrupts, can a jump table be constructed in C?
The most basic RISC-V vectored interrupt mode uses a jump table to implement an interrupt vector table(IVT). This is a bit like a set of goto statements in C. However, we cannot actually "goto" functions in C as a jump table does.
To declare a function as jump table in C these function attributes are defined on the function prototype:
- naked: So only code for the jump table is generated, disable the prologue/epilogue added but the the compiler.
- aligned: Use the strict memory alignment required by the RISC-V Interrupt Vector register, mtvec.
void riscv_mtvec_table(void) __attribute__ ((naked,aligned(16)));The jump table is implemented using inline assembler. The .org assembler directive ensures all jal jump instructions are at the correct offset in the jump table. The target functions are declared as C functions with the interrupt function attribute as above.
void riscv_mtvec_table(void) {
__asm__ volatile (
".org riscv_mtvec_table + 0*4;"
"jal zero,.handle_mtvec_exception;" /* 0 */
".org riscv_mtvec_table + 1*4;"
"jal zero,riscv_mtvec_ssi;" /* 1 */
".org riscv_mtvec_table + 3*4;"
"jal zero,riscv_mtvec_msi;" /* 3 */
".org riscv_mtvec_table + 5*4;"
"jal zero,riscv_mtvec_sti;" /* 5 */
".org riscv_mtvec_table + 7*4;"
"jal zero,riscv_mtvec_mti;" /* 7 */
".org riscv_mtvec_table + 9*4;"
"jal zero,riscv_mtvec_sei;" /* 9 */
".org riscv_mtvec_table + 11*4;"
"jal zero,riscv_mtvec_mei;" /* 11 */
);
}As it is a naked function it uses basic asm.
In the table above individual functions are defined for each interrupt and exception.
- Synchronous Exceptions (
riscv_mtvec_exception()) - these are called by first jumping to the label.handle_mtvec_exception(See the next section). - Software interrupts in machine and supervisor mode (
riscv_mtvec_msi(),riscv_mtvec_ssi()). - Timer interrupts in machine and supervisor mode (
riscv_mtvec_msi(),riscv_mtvec_ssi()). - External interrupts in machine and supervisor mode (
riscv_mtvec_msi(),riscv_mtvec_ssi()).
Accessing the Interrupted Stack Frame From C
How can the exception handler access the stack frame from the source of the exception?
The method I’m using here is based on the Linux kernel. At exception entry in entry.Sthe caller context is saved on the stack in a structure defined in ptrace.h . System calls can access the registers via functions defined in syscall.h to abstract the machine.
The example has a simplified flow and is embedded within C. The structure containing the registers, exception_stack_frame_t, is defined in include/riscv-abi.h. Some of the registers are deliberately not saved. The s0- s11 registers are callee saved, so can be expected to be saved when calling any C function. The gp and tp and sp registers are not saved as we are operating in a single binary/single stack.
#if __riscv_xlen == 32
typedef uint32_t uint_reg_t;
#elif __riscv_xlen == 64
typedef uint64_t uint_reg_t;
#endif
typedef struct {
// Global registers - saved if
uint_reg_t ra; // return address (global)
// Saved as they will not be saved by callee
uint_reg_t t0; // temporary register 0 (not saved)
uint_reg_t t1; // temporary register 1 (not saved)
#if !defined(__riscv_32e)
uint_reg_t t2; // temporary register 2 (not saved)
#endif
// Arguments are saved for reference by 'ecall' handler
// and as any function called expects them to be saved.
uint_reg_t a0; // function argument/return value 0 (caller saved)
uint_reg_t a1; // function argument/return value 1 (caller saved)
uint_reg_t a2; // function argument 2 (caller saved)
uint_reg_t a3; // function argument 3 (caller saved)
#if !defined(__riscv_32e)
uint_reg_t a4; // function argument 4 (caller saved)
uint_reg_t a5; // function argument 5 (caller saved)
uint_reg_t a6; // function argument 6 (caller saved)
uint_reg_t a7; // function argument 7 (caller saved)
#endif
#if !defined(__riscv_32e)
// Saved as they will not be saved by callee
uint_reg_t t3; // temporary register 3 (not saved)
uint_reg_t t4; // temporary register 4 (not saved)
uint_reg_t t5; // temporary register 5 (not saved)
uint_reg_t t6; // temporary register 6 (not saved)
#endif
} exception_stack_frame_t;There are no specific stack push/pop instructions for RISC-V, so we use sw and lw on a rv32* bit architecture. The immediate offset to the stack pointer is determined via the offsetof operator. In the example, these are wrapped in helper macros SAVE_REG and LOAD_REG.
#define SAVE_REG(REG) \
__asm__ volatile( \
"sw " #REG " , %0(sp); " \
: /* no output */ \
: /* immediate input */ "i" (offsetof(exception_stack_frame_t,REG)) \
: /* no clobber */)
#define LOAD_REG(REG) \
__asm__ volatile( \
"lw " #REG " , %0(sp); " \
: /* no output */ \
: /* immediate input */ "i" (offsetof(exception_stack_frame_t,REG)) \
: /* no clobber */)Macros to save and load the stack are composed from SAVE_REG and LOAD_REG. The sizeof operator allows us to move the stack pointer to explicitly allocate one instance of the exception_stack_frame_t on the stack.
The EXCEPTION_SAVE_STACK macro is shown below. The EXCEPTION_RESTORE_STACK macro is similar, but moves the stack pointer at the end of the sequence to free the exception_stack_frame_t instance. The SAVE_REG_NOT_E and LOAD_REG_NOT_E macros are defined to allow for differences between rv32e and other architectures.
The use of sizeof and offsetof operators allow the example to avoid magic numbers and size assumptions and bridge C to assembler in a more maintainable way.
#define EXCEPTION_SAVE_STACK \
/* Move stack frame */ \
__asm__ volatile( \
"addi sp, sp, -%0;" \
: /* no output */ \
: /* immediate input */ "i" (sizeof(exception_stack_frame_t)) \
: /* no clobber */); \
/* Ignore 0: zero */ \
SAVE_REG(ra); \
/* Ignore 2,3,4: Stack, global, thread pointers */ \
SAVE_REG(t0); \
SAVE_REG(t1); \
SAVE_REG_NOT_E(t2); \
SAVE_REG(a0); \
SAVE_REG(a1); \
SAVE_REG(a2); \
SAVE_REG(a3); \
SAVE_REG_NOT_E(a4); \
SAVE_REG_NOT_E(a5); \
SAVE_REG_NOT_E(a6); \
SAVE_REG_NOT_E(a7); \
SAVE_REG_NOT_E(t3); \
SAVE_REG_NOT_E(t4); \
SAVE_REG_NOT_E(t5); \
SAVE_REG_NOT_E(t6)Finally, we call into C and pass the stack pointer as the first argument in a0. As riscv_mtvec_exception is a standard C function we need to save the return address to ra, to ensure the C function returns to the point where it was called. The return value in a0 is copied to the sp on return, to potentially allow for a context switch (not implemented here).
void riscv_mtvec_table() {
__asm__ volatile(
...
".handle_mtvec_exception:");
EXCEPTION_SAVE_STACK;
__asm__ volatile(
// Current stack pointer
// Save to a0
"mv a0, sp;"
// Jump to exception handler
// Pass
"jal ra,riscv_mtvec_exception;" /* 0 */
// Restore stack pointer from return value (a0)
"mv sp, a0;"
);
EXCEPTION_RESTORE_STACK;
// Return
__asm__ volatile("mret;");Aligning C Functions using a Pragma
An alternate option to align a function in memory is to use a #pragma.
On the command line, we might apply -falign-functions=n to change function alignment globally. Using a #pragmathis can be applied to a region of code. The optimize pragma selects from the same options provided on the command line.
#pragma GCC push_options
// Ensure all ISR tables are aligned.
#pragma GCC optimize ("align-functions=4")
void riscv_mtvec_table(void) {
...
}
#pragma GCC pop_optionsIn my opinion, the function attribute is a cleaner way to specify a code generation option. However, a #pragma can be applied to many options and across an area of code. For example, we might generally optimize for size (-Os), but a time-critical interrupt handler may require speed optimization (-O2). A #pragma can make such local compiler option changes.
Weak Function Linking to Allow Optional ISR Implementation
The vector table above links to an independent function for each interrupt in the system. How do we avoid having to implement each ISR as a separate function? That can take up a lot of code space!
A weak alias can be used to map unimplemented functions to a default function, in this case, the riscv_nop_machine ISR.
e.g. In our example main.c program ISRs for msi and mei are not implemented. These are linked to the default NOP ISR, riscv_nop_machine. The weak linking to default ISRs is defined in src/vector_table.c for all interrupts.
static void riscv_nop_machine(void) __attribute__ ((interrupt ("machine")));
void riscv_mtvec_msi(void) __attribute__ ((interrupt ("machine"),
weak, alias("riscv_nop_machine") ));
void riscv_mtvec_mei(void) __attribute__ ((interrupt ("machine"),
weak, alias("riscv_nop_machine") ));
static void riscv_nop_machine(void) {
// Nop machine mode interrupt.
}Accessing the Machine
The real machine often has features and functions that have no equivalent in the C programming language abstract machine. The hardware needs to be accessed via instructions or the peripheral bus.
Using System Registers to Control Interrupts
How can we enable/disable interrupts using system registers in C?
The Control and Status registers(CSRs) used to control interrupts are accessed using special instructions on RISC-V. This requires inline assembler to access. GCC allows us to call functions and exchange C values via registers or immediate.
To load the vector table at riscv_mtvec_table, the function address is written mtvec to with the mode set to RISCV_MTVEC_MODE_VECTORED (1).
#define RISCV_MTVEC_MODE_VECTORED 1
...
// Setup the IRQ handler entry point, set the mode to vectored
csr_write_mtvec((uint_xlen_t) riscv_mtvec_table | RISCV_MTVEC_MODE_VECTORED);For this example, the csr_write_mtvec function is declared in a header include/riscv-csr.h, a header file with functions to access all system registers. Inline assembler is used to access the special instruction, and the extended __asm__ statement with input operands is used to specify the data register allocated by the C compiler containing the value to be written to mtvec.
static inline void csr_write_mtvec(uint_xlen_t value) {
__asm__ volatile ("csrw mtvec, %0"
: /* output: none */
: "r" (value) /* input : from register */
: /* clobbers: none */);
}Accessing Memory Mapped Registers to Manage the Timer
How do we translate the address of a memory-mapped IO (MMIO) register to a C pointer?
MMIO registers have an address within the system memory map. However, they are not equivalent to variables located in RAM, as they may have side effects on reading, writing, or possibly change asynchronously without access from software.
The machine mode timer mtime, located within the core local interrupt controller ( CLINT) is a good example on RISC-V. It is a 64-bit word located at an offset of 0xBFF8 within the CLINT, which is located at 0x2000000. (NOTE - This address is implementation-defined.)
Macros are defined within the driver header timer.h so the address does not need to be used directly.
#define RISCV_CLINT_ADDR 0x2000000
#define RISCV_MTIME_ADDR ( RISCV_CLINT_ADDR + 0xBFF8)The simplest way to access MMIO is to cast the address integer value (e.g. RISCV_MTIME_ADDR) to a volatile pointer to an unsigned integer the same size as the register (e.g. volatile uint64_t *).
- The standard integer types are defined in . These can be used to match the register width.
- Volatile is required as MMIO is not “memory” as understood by the abstract memory model. (In modern C/C++ this is one of the few acceptable uses of volatile.).
- Getting the word size right is important, as access to neighboring registers in MMIO may cause side effects.
volatile uint64_t *mtimecmp = (volatile uint64_t*)(RISCV_MTIMECMP_ADDR);However, in addition to register size we also need to consider bus size.
In the driver implementation timer.c when __riscv_xlen is set to 32 a set of high and low registers are defined.
volatile uint32_t * mtimel = (volatile uint32_t *)(RISCV_MTIME_ADDR);
volatile uint32_t * mtimeh = (volatile uint32_t *)(RISCV_MTIME_ADDR+4);The implementation of mtimer_get_raw_time() shows how the registers are read via pointer de-referencing with the * operator.
uint64_t mtimer_get_raw_time(void) {
#if ( __riscv_xlen == 64)
// Atomically read the 64 bit value
return *mtime;
#else
uint32_t mtimeh_val;
uint32_t mtimel_val;
do {
mtimeh_val = *mtimeh;
mtimel_val = *mtimel;
// Read mtimeh again. If mtimel has overflowed and mtimeh incremented
// then we will detect it here and loop again.
// Do to the low frequency of mtimeh this iteration should be rare.
} while (mtimeh_val != *mtimeh);
return (uint64_t) ( ( ((uint64_t)mtimeh_val)<<32) | mtimel_val);
#endif
} The implementation of mtimer_set_raw_time_cmp() shows how the registers are written via pointer de-referencing with the * operator.
void mtimer_set_raw_time_cmp(uint64_t clock_offset) {
uint64_t new_mtimecmp = mtimer_get_raw_time() + clock_offset;
#if (__riscv_xlen == 64)
// Atomic bus access
*mtimecmp = new_mtimecmp;
#else
// AS we are doing 32 bit writes, an intermediate mtimecmp value may cause spurious interrupts.
// Prevent that by first setting the dummy MSB to an unachievable value
*mtimecmph = 0xFFFFFFFF;
// set the LSB
*mtimecmpl = (uint32_t)(new_mtimecmp & 0x0FFFFFFFFUL);
// Set the correct MSB
*mtimecmph = (uint32_t)(new_mtimecmp >> 32);
#endif
}Both implementations have specialized 32-bit versions.
- There is no way to do an atomic 64-bit timer count read over a 32-bit bus, so we need to read each 32-bit word independently and confirm there has been no overflow from low to high word of mtime.
- There is no way to do an atomic 64-bit compare value write a 32-bit bus, so we need to ensure the transient mtimecmp register value does not cause an interrupt. The MSB is set to an impossible value before setting the LSB to the real value, followed by the real MSB value.
Using Compiler Macros to Customize for the Architecture
How can we select different implementations depending on architecture variants?
RISC-V is a very customizable architecture, and the code may need to change to match the target architecture. The compiler defines system specific pre-defined macros for this purpose.
For example, the mcause register, like many CSRs, places a control bit in the MSB. This changes depending on if we are an rv32* or rv64* architecture. The __riscv_xlen macro can be used to locate the MSB, as is done in riscv-csr.h. I've listed some common ones on my ISA & Extensions Quick Reference, along with links to the source specification documents.
The example below defines nop register access macros for RV32E targets that have fewer registers.
#define MCAUSE_INTERRUPT_BIT_MASK (0x1UL << ((__riscv_xlen-1)))
#if defined(__riscv_32e)
// Ignore registers not implemented in rv32e
#define SAVE_REG_NOT_E(REG)
#define LOAD_REG_NOT_E(REG)
#else
// Handle all registers
#define SAVE_REG_NOT_E SAVE_REG
#define LOAD_REG_NOT_E LOAD_REG
#endifBuilt-in functions
Does the compiler offer a built-in and/or portable way to access the machine functionality?
For some features, there are built-in functions provided by the compiler, and these may be portable across architectures.
- Atomics and Synchronization built in functions to perform safe memory access when other cores may be accessing the same memory. (Modern C11 also defines standard atomic functions.)
- Vector Extension to access SIMD features. There are also intrinsic functions that match the instruction set of the underlying architectures (such as Intel’s AVX/SSE/MMX or NEON), although I can’t see any for RISC-V’s vector extensions right now.
- Target Built-ins to access target registers and instructions. The RISC-V section is quite light here.
The example for this article does not use any built-in functions, as the target is a simple single hart RV32I. I'd like to explore these in another article.
Bringing it All Together
This article so far has looked at building blocks only, let’s put together the simple program that configures and responds to timer interrupts and handles synchronous exceptions (using a syscall example).
The example includes the following source files:
- src/startup.c — Entry/Startup/Runtime
- src/main.c — Main Program
- src/timer.c / include/timer.h — Timer Driver
- src/vector_table.c / include/vector_table.h — Interrupt Vector Table
- include/riscv-csr.h / include/riscv-interrupts.h — RISC-V Hardware Support
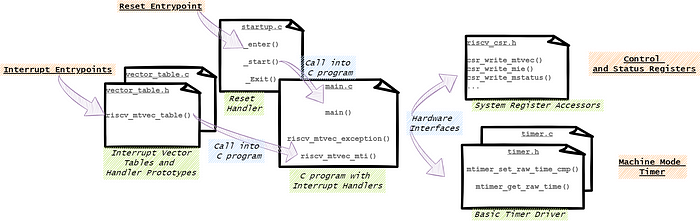
Implementing Interrupt Handlers
The handler definitions are marked with GCC interrupt function attributes. This will ensure the stack is saved at entry and restored on return, and the mret, sret or uret instruction is used to return. The handler implementation does not need this attribute, assuming the declarations invector_table.h are included.
The timer interrupt service routine handles the interrupt by adding an extra second to mtimecmp. That will disable the current mti interrupt and schedule the next.
// The 'riscv_mtvec_mti' function is added to the vector table by the vector_table.c
void riscv_mtvec_mti(void) {
// Timer exception, re-program the timer for a one second tick.
mtimer_set_raw_time_cmp(MTIMER_SECONDS_TO_CLOCKS(1));
timestamp = mtimer_get_raw_time();
}Implementing Exception Handlers
The exception handler decodes the mcause register to determine what exception has occurred. In the case of an environment call from m mode, our handler simply increments ecall_count so we can observe the exception. Before returning, the mepc register is incremented by the size of one instruction word. This value is restored to thepc on return from exceptions with mret, so we need to move to the next instruction.
// The 'riscv_mtvec_exception' function is added to the vector table by the vector_table.c
// This function looks at the cause of the exception, if it is an 'ecall' instruction then increment a global counter.
exception_stack_frame_t *riscv_mtvec_exception(exception_stack_frame_t *stack_frame)
uint_xlen_t this_cause = csr_read_mcause();
uint_xlen_t this_pc = csr_read_mepc();
//uint_xlen_t this_value = csr_read_mtval();
switch (this_cause) {
case RISCV_EXCP_ENVIRONMENT_CALL_FROM_M_MODE:
ecall_count++;
// Make sure the return address is the instruction AFTER ecall
csr_write_mepc(this_pc+4);
break;
}
return stack_frame;
}Other exceptions are not handled. What is the correct response for an exception that can’t be handled? In a conventional application, a call to something like abort()might be made. I’ve usually taken one of three approaches:
- If the debugger is connected, call the debugger breakpoint instruction, for RISC-V that is the ebreak instruction.
- If targeting specific hardware with hard reset support, perform a hard reset.
- Perform a soft reset. Re-initialize and restart the firmware.
For the example, I’ve implemented the last option, a simple soft reset. It has been done by making the _entry() function address the exception return address via mepc.
extern void _enter(void);
...
exception_stack_frame_t *riscv_mtvec_exception(exception_stack_frame_t *stack_frame) {
uint_xlen_t this_cause = csr_read_mcause();
switch (this_cause) {
...
default:
// All other system calls.
// Unexpected calls, do a soft reset by returning to the startup function.
csr_write_mepc((uint_xlen_t)_enter);
break;
}
...
}Implementing a System Call
The ecall instruction allows a context switch from user software into an exception handler. These are often used for system calls, such as a Linux user space function calling into the kernel to perform a system task. For this example we’re just going through the motions of passing data in and out of an exception handler.
The instruction does not take parameters, instead before executing the instruction, software loads registers according to a calling convention. One calling convention is defined by the SBI Binary Encoding. Another is defined by the Linux kernel, in thesyscall.h file. I’ve defined a dummy calling convention below, a0 as the argument, a0 also as the return value and a7 as the function ID (or a3 for RV32E).
The example uses explicit register variables to load the registers appropriately. These are custom extensions of the almost obsolete registerstorage class specifier.
static unsigned long int riscv_ecall(ecall_function_id_t function_id, unsigned long int param0) {
// Pass and return value register.
register unsigned long a0 __asm__("a0") = param0;
// Use the last argument register as call ID
#ifdef __riscv_32e
// RV32E only has a0-a3 argument registers
register unsigned long ecall_id __asm__("a3") = function_id;
#else
// Non -e variants have has a0-a7 argument registers
register unsigned long ecall_id __asm__("a7") = function_id;
#endif
__asm__ volatile("ecall "
: "+r"(a0) /* output : register */
: "r"(a0), "r"(ecall_id) /* input : register*/
: /* clobbers: none */);
return a0;
}The RISC-V newlib has an implementation in libgloss/riscv/internal_syscall.h.
Handling a System Call
Implementing a system call relies on accessing the registers saved at the point of entry. For this example, they have been saved by src/vector_table.c and passed to riscv_mtvec_exception() as a struct ( exception_stack_frame_t), defined in include/riscv-abi.h.
typedef struct {
...
uint_reg_t a0; // function argument/return value 0 (caller saved)
uint_reg_t a3; // function argument 3 (caller saved)
#if !defined(__riscv_32e)
...
uint_reg_t a7; // function argument 7 (caller saved)
#endif
...
} exception_stack_frame_t;
#if defined(__riscv_32e)
#define RISCV_REG_LAST_ARG a3
#else
#define RISCV_REG_LAST_ARG a7
#endif
exception_stack_frame_t *riscv_mtvec_exception(exception_stack_frame_t *stack_frame) {
...
switch (this_cause) {
case RISCV_EXCP_ENVIRONMENT_CALL_FROM_M_MODE: {
// Dummy syscall handling...
unsigned long int ecall_id = stack_frame->RISCV_REG_LAST_ARG;
if (ecall_id == ECALL_INCREMENT_COUNT) {
unsigned long int arg0 = stack_frame->a0;
stack_frame->a0 = arg0+1;
}
// Make sure the return address is the instruction AFTER ecall
csr_write_mepc(this_pc + 4);
break;
}
...The Main Function
The main() function configures the interrupts before entering an endless loop. The flow is:
- Disable all interrupts. (via mstatus.mie and mie )
- Configure the interrupt vector table. (via mtvec)
- Set the timer expiry. (via mtimecmp)
- Enable the timer interrupt. (via mie)
- Enable all interrupts. (via mstatus.mie)
int main(void) {
// Global interrupt disable
csr_clr_bits_mstatus(MSTATUS_MIE_BIT_MASK);
csr_write_mie(0);
// Setup the IRQ handler entry point, set the mode to vectored
csr_write_mtvec((uint_xlen_t) riscv_mtvec_table | RISCV_MTVEC_MODE_VECTORED);
// Setup timer for 1 second interval
mtimer_set_raw_time_cmp(MTIMER_SECONDS_TO_CLOCKS(1));
// Enable MIE.MTI
csr_set_bits_mie(MIE_MTI_BIT_MASK);
// Global interrupt enable
csr_set_bits_mstatus(MSTATUS_MIE_BIT_MASK);
...After configuring interrupts it enters a busy loop. The wfi instruction should place the CPU in a low-power state until an interrupt occurs, rather than just busy looping. There is no reason to call ecall other than to test out the riscv_mtvec_exception, and local_ecallcount only exists to test passing data back and forth to the exception.
static inline void riscv_wfi(void) {
__asm__ volatile("wfi");
}
....
int main(void) {
...
// Busy loop
// Keep a local counter of how many times `ecall` has been executed.
unsigned int local_ecallcount = 0;
// Busy loop
do {
// Wait for timer interrupt
riscv_wfi();
// Try a synchronous exception - ask the exception handler to increment our counter.
local_ecallcount = riscv_ecall(ECALL_INCREMENT_COUNT, local_ecallcount);
} while (1);
...
}Building and Running
PlatformIO IDE
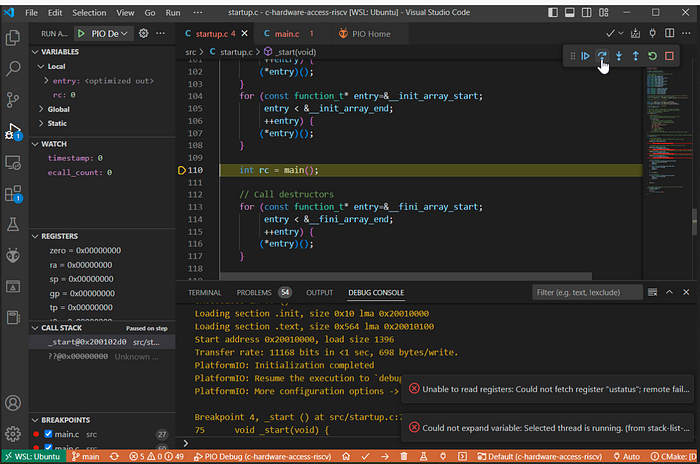
The PlatformIO IDE is a device and vendor-independent development environment for embedded systems For this project ithas been configured to target QEMU emulating a hifive1 board.
The IDE can step through from before main(), and into each interrupt handler.
Command Line/CI
For this example GitHub actions are implemented with Docker, CMake and Xpack-GCC.
CMake Build Environment:
GitHub/Docker CI
PlatformIO can also be used from the CLI and in CI. The purpose here is to show a few options for development that are not tied to any particular silicon vendor.
Conclusion
This is a long article for a relatively simple piece of code. The complexity was added by building from the bottom up, investigating each step, and looking into the toolchain features that enable us to break out of the standard C execution model.
The purpose of this article has been to capture experience building firmware for custom SoCs based on ARM Cortex-M, RISC-V cores, and even the 8051 from the ground up. With the emergence of RISC-V, the opportunity to build and target such custom platforms is growing. For small deeply embedded firmware, building a single code base in C can make life easier.
Here are a few similar themed articles that can elaborate on this topic for other languages and processor architectures:
- https://zyedidia.github.io/blog/posts/1-d-baremetal/ — Writing a bare-metal RISC-V application in D
- https://florian.noeding.com/posts/risc-v-toy-cpu/cpu-from-scratch/ — How a CPU works: Bare metal C on my RISC-V toy CPU
- https://interrupt.memfault.com/blog/zero-to-main-1 — From Zero to main(): Bare metal C (For ARM)
- A Baremetal Introduction using C++ — Bare-metal for RISC-V from a C++ perspective.
Originally published at https://five-embeddev.com on March 20, 2023.
Acknowledgment
This article and example are based on low-level support libraries from chip and processor vendors. For example, for ARM Cortex-M cores the CMSIS library, and NXP LPCOpen library, and for RISC-V SiFive provides its Freedom Metal Library as one example. However, in these libraries most source code is in assembler, such as startup_ARMCM0.S or RISC-V entry.S, my goal has been to raise the abstraction of this code to C.