Coding in C for MCUs: Sort Structs to Save Code Size
Exploring the Impact of Hardware Architecture on Code
This post explores two things. Firstly, a handy way to save code size on ARM Cortex-M-based MCUs with limited resources. Secondly, it looks at the impact of the hardware architecture on meeting software requirements. In particular, it looks at memory rows and alignment.
An Easy Code Size Optimization
I’d like to share a simple coding style for C on ARM Cortex-M0 embedded devices that will save on code size.
Consider the NXP LPC111x series, which has between 4k and 64k of flash available. These and similar devices are very limited in resources, and every byte counts.
Looking at the code samples below, which of the two structures will result in more efficient code for functions that access it.
- This organically defined one:
struct driver_info {
uint8_t hw_addr[6]; // 0-5
uint32_t some_word; // 6-10 (8-12)
bool flag1; // 11 (13)
enum {state_1=0, state_2=0x100, state_3=0xfeed} state;
// 12-13 (->14-15)
bool flag2; // 14 (16, pad: 17, 18, 19)
void *ptr_to_something; // 15-18 (20)
uint32_t data_buffer[4]; // 19-35
bool flag3; // 36
};2. This neatly sorted one:
struct driver_info{
bool flag1; // 0
bool flag2; // 1
bool flag3; // 2
uint8_t hw_addr[6]; // 4-9
enum {state_1=0, state_2=0x100, state_3=0xfeed} state;
// 10-11
void *ptr_to_something; // 12-15
uint32_t some_word; // 16-19
uint32_t data_buffer[4]; // 20-35
};Can the ordering of declarations change how the compiler generates code? You can see for yourself on compiler explorer:
Version 2 uses fewer instructions. When the structure is accessed many times those few bytes can add up. I have saved a few hundred to thousands of bytes of code space on systems with 16Kb to 64 Kb, where every byte counts. (It will depend on the application of course.)
To save code size, declare structure members in order of smallest to largest.
However, that leaves a question… why?
Why Does Declaration Order Matter?
There are several factors that affect code generation here:
- Data alignment and the way that data is retrieved on the bus.
- The offset from the structure base address, and the instruction encoding of the offset according to the ISA.
Alignment
A word is aligned when it is placed at an offset that is a multiple of its size.
- 8-bit byte access: no alignment, all address locations.
- 16-bit half-word access: every 2 bytes, even address locations.
- 32-bit word access: every 4 bytes, addresses 4n. e.g. 0, 4, 8 ..
Unaligned access occurs when the odd locations between those aligned locations are accessed with larger word sizes. e.g. a 32bit read from address 3, or a 16 bit read from address 1.
Data Alignment and Bus Accesses
Why is alignment important? Hardware architecture often reflects a natural alignment.
A small micro-controller such as the LPC111x series has a very simple interface to memory. The bus and interface to SRAM are 32-bits wide, which means 4 bytes are always read and/or written simultaneously in one bus cycle. Those 4 bytes need to be aligned.

Aligned and Unaligned Accesses
What happens if 32-bits or 16-bits are accessed at an odd location that is not aligned? The bus operation must be repeated for each row accessed.
For example, consider two different writes to memory:
Aligned: (uint16_t*)(0x1234566) =0xabcd;
Unaligned: (uint16_t*)(0x1234567) =0xabcd;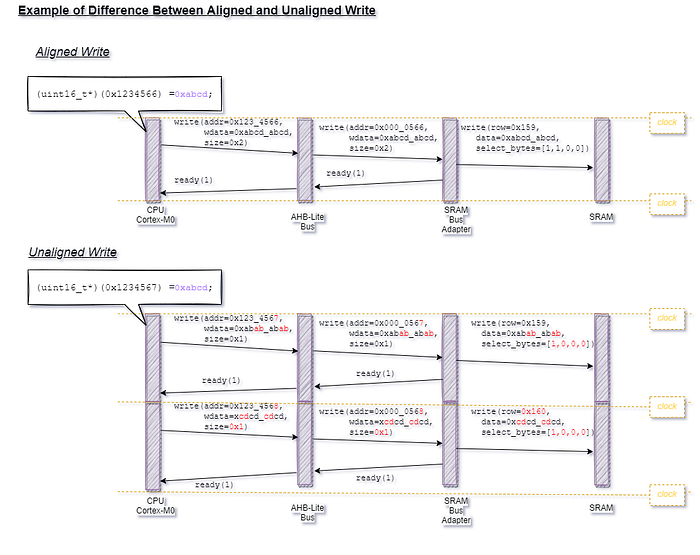
For a Cortex-M0 these multi-row unaligned operations are simply not implemented in hardware. Unaligned access is not allowed at an ISA level. This is because the hardware has been optimized to be as absolutely small as possible.
Offsets and Addressing Modes
A structure in C is represented by a pointer to the start of the structure in memory. A read or write to a member of the structure requires calculating the address of the member by adding the offset of the member to the base pointer.
This is such a common operation that the instruction set supports it directly, by an immediate offset addressing mode. The instruction word encodes the offset of the member into a field in the instruction word. For an ARM ThumbV1 ‘load’ using a 16-bit instruction word, the size of this offset is 5 bits.
How large is the immediate offset for 5 bits? The opcode reference can tell us:
- 8-bit byte access: 32 bytes.
- 16-bit half-word access: 64 bytes.
- 32-bit word access: 128 bytes.
(As all memory accesses are aligned, the offset has been designed to be shifted left according to the memory alignment of the word size.)
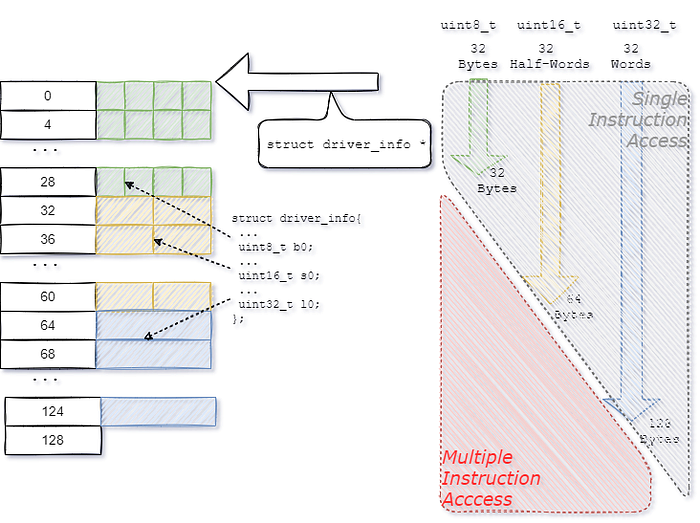
Any access outside the range of will require larger instruction words to encode a large immediate offset, or more instructions to calculate the address to the member and store it in a register.
In Summary, Why Does This Optimization Work?
There are three main points:
- The compiler can’t re-order structure members, so the optimizer is restricted.
- We save code size by encoding member offsets in the immediate field of the smaller instruction word.
- We also save RAM usage by reducing padding due to fewer alignment changes.
So What?
This post is really about the interaction of hardware architecture and software.
The optimization described here applies only to a very small subset of software development activities. However, it is possibly also the simplest hardware to understand. Therefore it may be one of the simplest examples of the impact of hardware architecture choices on software.
A common example of hardware architecture and software design interacting is the effect of cache over the simpler estimates order estimates of performance. For example, the original C++ STL included the std::map container, using a tree structure that gives a theoretical performance. However, each traversal of the tree is a potential cache miss. C++11 added the std::unordered_map container as it can have better cache performance due to a flatter structure with fewer cache misses. (This links to a broader topic of efficiency vs speed covered on the Algorithms + Data Structures = Programs podcast.)
Conclusion
Any software that needs to push the limits of performance, be it ultra-low size to keep the cost down, or consistent high performance, needs to be aware of the effect of the design choices of the hardware platform can have on the software.
Originally published at http://www.shincbm.com on February 18, 2022.
